Introduction
L’incendie qui a eu lieu chez OVH dans la nuit du 9 au 10 mars a eu, comme pour beaucoup de monde, des impacts sur notre infrastructure. Par chance, cela n’a pas gravement impacté notre activité.
Par chance ? En fait non, nous n’avons pas compté sur la chance. Si la situation a généré un certain stress dans notre équipe et nous a forcé à revoir certaines priorités, nous avions fait le nécessaire pour garantir la continuité de nos opérations et l’intégrité des données de nos clients et de nos utilisateurs.
Aussi grave et impressionnant un tel incident puisse être, vous pouvez vous aussi vous y préparer et faire en sorte d’encaisser la panne avec sérénité et méthode, sans impact majeur sur votre activité. Dans cet article, nous vous présentons quelques grands principes à respecter pour gérer les pannes de ce genre.
Des pannes interviennent tous les jours
Un centre de donnée, ça ne part pas en fumée tous les jours ; vous pourriez vous dire qu’un tel incident est très peu probable et ne devrait pas se reproduire de sitôt.
Et vous auriez raison.
Mais en réalité, les pannes sont aussi diverses que fréquentes. Aujourd’hui il s’agit d’un incendie, demain ce sera autre chose : un disque dur qui lâche, une alimentation qui grille, une attaque qui cible votre organisation ou votre prestataire, une erreur de manipulation, un vol, un rançongiciel qui chiffre vos données... On pourrait enrichir cette liste encore longtemps.
Ce qui importe ce n’est pas tant la fréquence des pannes que la résilience de votre organisation.
Une panne n’est grave que si vous n’avez pas de plan.
Être prêt à affronter des pannes
La première question à se poser est celle du risque acceptable :
- combien de temps vos services peuvent-ils être interrompus sans nuire gravement à votre activité ?
- quelle est la valeur de vos données ? Dit autrement : si vous perdez vos données, votre activité peut-elle continuer ?
- quel volume de données pouvez-vous accepter de perdre sans que cela n’impacte définitivement et irrémédiablement votre activité ?
La réponse que vous donnez souvent à cette question est « je ne peux pas tolérer la moindre perte de données ». Mais d’une part cela n’est pas réaliste (on ne peut pas garantir à coup sûr qu’aucune donnée ne sera perdue, ni qu’un service ne sera jamais interrompu), d’autre part cela coûte horriblement cher – bien plus cher que ce que vous êtes très probablement prêt à dépenser.
Des risques que vous considérez comme acceptables découleront vos besoins et les coûts associés.
Répondre à ces questions doit être fait en toute lucidité, et en toute honnêteté intellectuelle, sinon c’est la déception assurée.
Bien sûr la réponse n’est pas universelle : si des vies humaines dépendent de vos systèmes, si des flux financiers importants sont en jeu, les moyens qui seront mis en place seront plus importants que si vos systèmes manipulent des données de faible importance stratégique.
Prenons l’exemple d’Algoo. La survie de notre activité dépend de la bonne conservation des données que nos utilisateurs et clients nous confient. Toutefois, en cas de panne, une interruption de service est tolérable.
- dans le cas d’un incident majeur tel qu’un incendie dans notre centre de données, le temps de rétablissement serait de l’ordre de 24h. Une perte de données de 24h maximum pourrait alors intervenir, compte-tenu de notre politique de sauvegardes.
- dans le cas d’une panne matérielle – un disque dur qui tombe en panne par exemple, la panne serait invisible pour nos utilisateurs, aucune donnée ne serait perdue.
Dans votre démarche, la première chose à faire est surtout de ne pas de redouter la prochaine panne mais plutôt de l’attendre de pied ferme. De s’y être préparé. D’ailleurs, sur le plan stratégique, il est bien plus important de prévoir les pannes et de rôder les processus de rétablissement de service que de mettre en place des mécanismes pour éviter les pannes (on ne pense jamais à tous les cas de pannes et on ne peut de toute façon pas s’en prémunir)
On parle de Plan de Continuité d’Activité (PCA) et Plan de Reprise d’Activité (PRA).
Le mieux est l’ennemi du bien
Un plan de reprise d’activité (PRA ou Disaster Recovery Plan en anglais) imparfait est meilleur qu’un plan inexistant.
Il faut bien commencer quelque part, il sera ensuite temps d’améliorer les choses. De toute manière, il est nécessaire de s’adapter constamment aux changements ; la gestion des pannes et la résilience relèvent d’un processus perpétuel plus que d’une solution définitive.
Travailler de manière incrémentale est important et reste la meilleure méthodologie :il serait dommage d’avoir un plan presque parfait mais pas opérationnel.
Des sauvegardes, du monitoring et des procédures
La première étape pour se remettre d’une panne est d’avoir une copie des données en lieu sûr. En effet, si votre serveur de production tombe en panne, il est probable que vous ne puissiez pas récupérer vos données.
Surveiller votre infrastructure permet de détecter des pannes voire de les anticiper. La détection rapide d’une panne est le premier rempart face à l’interruption de service. D’une part c’est un moyen d’être plus réactif, d’autre part cela peut éviter que les choses s’aggravent. Un incendie localisé est beaucoup plus facile à maîtriser qu’un incendie qui a eu le temps de se propager.
En cas de panne ou d’incident, les procédures vous permettront de vous concentrer sur le rétablissement du service, sur la restauration des données et éviteront les erreurs et les phases de réflexion du type « quelle est la meilleure stratégie pour faire ceci ou faire cela ? »
Qu’est-ce qu’une bonne sauvegarde ?
Une bonne sauvegarde, c’est plusieurs choses :
- Des données à jour : une sauvegarde faite il y a deux mois est mieux que rien, mais vous aimeriez sans doute avoir perdu moins d’informations récentes.
- Un process automatique : des sauvegardes automatiques évitent la charge mentale associée et l’erreur humaine. La loi de Murphy aidant, c’est le soir où la personne en charge des sauvegardes a une urgence et n’a pas fait la sauvegarde comme voulu que la catastrophe va arriver.
- Des tests réguliers : vous ne pouvez savoir si une sauvegarde fonctionne que si vous l’avez testée. Si vous ne la testez pas, vous courrez le risque de manquer un élément critique à la restauration de votre production. Tester est la seule manière de s’en rendre compte. Le jour où vous aurez besoin de cette sauvegarde, vous serez dans l’urgence. Une sauvegarde qui fonctionne bien est la garantie d’un service restauré rapidement, complètement, avec un maximum de sérénité.
- un processus surveillé : l’automatisation a un défaut : elle peut échouer silencieusement. Vous devez avoir un moyen de détecter un processus de sauvegarde défaillant.
- des fichiers accessibles : une sauvegarde ne vaut pas grand-chose si elle n’est pas accessible parce qu’elle a disparu avec la panne, parce qu’elle est coincée dans un centre de données inaccessible à cause de la panne, ou parce qu’elle est chez vous, complète et prête à l’emploi mais sans possibilité de renvoyer sur vos serveurs dans des délais raisonnables (attention à la connectivité).
Anticiper ou détecter la panne avec du monitoring
Pour remettre votre infrastructure en place, la première chose à faire est d’identifier qu’elle est hors-service ou sur le point de l’être.
Pour cela, vous devez la surveiller.
Une pléthore d’outils existent pour surveiller différents éléments du système, notamment sa température, l’espace de stockage, l’utilisation des ressources voire la présence d’activité suspecte. Ces outils de monitoring vous envoient des alertes quand une des sondes détecte une situation qui demande de l’attention – idéalement avant que cela devienne critique.
Par ailleurs, comme évoqué en préambule, plus une anomalie est détectée rapidement, plus il y a de chances de contenir l’incident et d’en limiter les conséquences.
Des procédures et de la documentation pour savoir quoi faire
Lorsqu’une panne intervient, vous êtes préoccupé ; l’existence de documentation et de procédures vous permettra de limiter vos besoins de réflexion dans le stress et l’urgence.
Vous devez pouvoir appliquer sereinement des étapes claires et simples pour reconstruire votre système à partir des données et du code.
Un plan de reprise d’activité doit être préparé. Avoir des procédures automatiques est idéal, mais n’est pas obligatoire pourvu que les procédures soient bien documentées.
Automatiser peut être coûteux et il est acceptable d’avoir des étapes manuelles. Ces étapes manuelles gagneront à être automatisées dans un contexte d’amélioration continue. L’automatisation n’est utile que si elle fait gagner du temps et automatiser des étapes simples à suivre ou rarement effectuées n’est pas nécessaire, d’autant que cela peut induire des coûts de maintenance. Elle est en revanche très intéressante pour éviter des opérations manuelles complexes sources d’erreurs.
Lors d’une panne, vous devez avoir la certitude que vos procédures fonctionnent.
Il faut donc que vous les testiez régulièrement. Votre activité évolue et le monde autour aussi, ces procédures sont donc également amenées à évoluer. Ce test régulier vous amènera à automatiser certaines étapes et probablement à utiliser des outils de déploiement automatiques.
Ne pas mettre tous ses œufs dans le même panier
Le principe
On voit rapidement que pour se préparer à gérer des pannes, il faut s’appuyer sur différents outils :
- l’infrastructure de production,
- les sauvegardes,
- les outils de surveillance,
- les outils de déploiement automatiques
- ...
Le cas échéant, chacun de ces outils peut être redondé pour limiter l’impact d’une panne.
Cela va sans dire, mais ça va encore mieux en le disant : ne mettez pas tout au même endroit, même si cela semble plus pratique au premier abord.
Ne pas mettre tous les œufs dans le même panier permet de limiter l’étendue d’une panne, puisqu’elle ne touchera qu’un élément de l’infrastructure. Cela facilite également la remise en marche puisqu’on ne devra restaurer qu’une partie et qu’on pourra s’appuyer sur les autres éléments, fonctionnels.
Pour illustrer cela, nous présentons dans la partie suivante les lignes directrices et concepts-clés de notre infrastructure.
L’infrastructure Algoo
Notes avant-propos :
- dans les descriptions suivantes l’expression « pas au même endroit » signifie « pas au même endroit géographiquement » (villes différentes, idéalement aussi loin l’une de l’autre que possible). En effet, une catastrophe touchant une zone industrielle pourrait impacter des centres de données de deux fournisseurs concurrents en même temps. Il vaut mieux viser des endroits géographiques différents que des fournisseurs différents.
- *envisager des fournisseurs différents est encore mieux : les interfaces de gestion sont ce qu’on appelle des points de défaillance unique (SPoF – Single Point of Failure en anglais)*
- une panne de cette interface vous empêchera d’administrer vos serveurs – hors, une panne de cette interface pourrait malheureusement venir d’une panne qui vous touche vous aussi. Si vous utilisez des opérateurs différents, il est peu probable que leurs interfaces de gestion tombent en panne en même temps et vous pourrez rebondir.
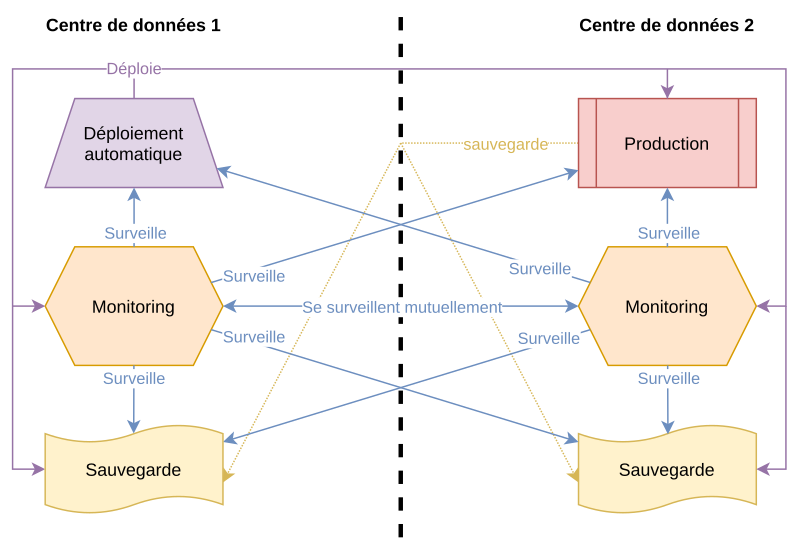
Quelques points importants :
- Le système de déploiement n’est pas au même endroit que la production : si une panne touche le centre de donnée de votre infrastructure de production, c’est justement à ce moment-là que vous avez besoin que votre système de déploiement. En les séparant géographiquement, une panne touchant votre système de déploiement ne touchera pas votre infrastructure de production et inversement. Vous pourrez alors restaurer votre système sereinement.
- *L’infrastructure de production est surveillée par un système de monitoring qui n’est pas dans le même centre de donnée : si une panne touche votre infrastructure, vous voulez recevoir des alertes, et ce n’est pas possible si la panne touche également le système de monitoring.
- Le système de surveillance est redondé : ainsi une panne du système de surveillance n’empêchera pas les alertes de vous avertir. L’astuce consiste à avoir deux systèmes de surveillances redondés et se surveillant mutuellement.
- Plusieurs sauvegardes, à des endroits différents : quand un des systèmes de sauvegarde plante, on a le temps de le reconstruire à partir de l’autre ou à partir de la production. Avec une seule sauvegarde, si elle plante, c’est la panique et le rush pour en reconstruire une (en croisant les doigts pour que l’infrastructure de production ne tombe pas en panne dans l’intervalle).
- Plusieurs jours de sauvegardes : cela permet de restaurer des versions antérieures si nous nous rendons compte de la présence d’un problème bloquant identifié avec du retard (exemple : compromission des serveurs de production).
Nous avons fait le choix de ne pas redonder géographiquement notre infrastructure de production. Cela signifie qu’en cas de panne importante, nos services pourront être indisponibles le temps qu’on reconstruise notre infrastructure.
Grâce à nos procédures, nos sauvegardes et notre documentation nous savons faire cela.
Redonder géographiquement une infrastructure de production est complexe et coûteux. Aujourd’hui, nous avons fait le choix de ne pas le faire. Ce n’est pas un choix définitif mais une démarche pragmatique d’amélioration continue. Il est préférable d’avoir un système sujet à panne mais qu’on sait reconstruire rapidement plutôt qu’un système plus robuste a priori mais que l’on ne sait pas reconstruire.
Note : nous avons également en place certains mécanismes de résilience plus forte. Par exemple nos serveurs sont configurés en RAID 1+0, ce qui fait que la défaillance d’un disque dur est totalement transparente pour les utilisateurs et la continuité de service (dans la mesure où les différents appareils ne tombent pas en panne en même temps). Toutefois, il faut bien garder à l’esprit que cela n’affranchit en aucun cas de mettre en place des sauvegardes : ce n’est pas la même chose d’écrire en temps réel des données redondées et de copier régulièrement et dans un autre endroit un jeu de données dont la durée de vie sera totalement découplée. Pour illustrer concrètement cela, la mise en place de disques redondés va permettre d’améliorer notre continuité d’activité, là où la mise en place de sauvegardes va permettre d’assurer la reprise d’activité (en cas de défaillance forte).
Placer son serveur ou ses sauvegardes dans ses locaux – une fausse bonne idée
Même si l’idée est tentante, il n’est pas forcément plus pertinent de placer vos informations et services stratégiques dans vos locaux. Ils ne sont probablement pas plus sûrs qu’un centre de données, bien au contraire.
Un centre de données est géré par des experts, qui vont travailler au quotidien à éviter vols, intrusions, incendies. Ce n’est très probablement pas le cas de vos locaux.
Même s’il peut être rassurant d’avoir ses sauvegardes « chez soi », tout cela s’applique aussi pour les sauvegardes derrière une connexion domestique, avec un facteur aggravant : la restauration d’une sauvegarde entreposée chez vous risque de se faire très lentement compte-tenu des débits montants des connexions internet personnelles.
Dans ces deux cas, la redondance dans des centres de données reste la seule solution sérieuse.
Mais alors, que faire ?
La première chose à faire est de faire confiance à vos partenaires en informatique.
S’ils vous disent que des sauvegardes doivent être mises en place, s’ils vous disent qu’il faut améliorer l’infrastructure informatique, écoutez-les. Inutile de lancer des actions à bâtons rompus du jour au lendemain, mais optez pour une approche amélioration continue.
Comment savoir si ce qu’on vous propose est approprié ou trop coûteux ?
La bonne manière d’envisager les coûts en termes de sécurisation des données et des services est d’avoir une approche inversée. Ne vous posez pas la question « combien ça coûte » mais « combien cela me coûtera-t-il si je perds les données ? ».
Une infrastructure informatique résiliente, sauvegardée, monitorée, robuste, c’est l’assurance d’une activité pérenne et durable.
Nous pouvons vous aider à mettre en place ce dont vous avez besoin pour assurer la pérennité de votre organisation.
N'hésitez pas à nous contacter !